Безопасный счёт вечности
 |
Ей было всего 37. Работала в медсанчасти, устала, как и вся страна. И в какой-то момент решила хоть кому-то довериться, когда позвонили «представители Госуслуг»: мягкий голос, уверенный тон, «служебные персона» на другом конце провода. Сценарий проверенный — «ваш личный кабинет взломали», «срочно спасайте деньги», «переведите всё на безопасный счёт».
Где-то в тот момент, когда она бегала по банкам и продавала личные вещи, государственная машина могла бы вмешаться. Но не вмешалась. 13 ноября её нашли в водоёме у базы отдыха «Бодрость» под Асбестом. Символично название, правда? Пока одни отдыхают, другие тонут — в буквальном и метафорическом смысле. Эпоха цифрового благополучия, но смерти по старым схемам Миллионы держат на телефонах «Мир», «Госуслуги», «Госключи», «Автокод», и ещё сто приложений, где за каждым QR-кодом живёт бюрократический членистоногий аппарат. Нам обещают «цифровое удобство», «защиту данных» и «российское облако», но в реальности это облако висит над каждым из нас — с громом, молнией и фразой «ваш личный кабинет пытаются взломать». Баланс цифровых иллюзий и реальных смертей уже пора свести в таблицу: сколько граждан умерло из-за мошенников, потому что оператор связи выдал симку «по скану неизвестно чьего паспорта», а силовики на горячей линии разводят руками? Где все те, кто так любит говорить о «национальной безопасности»? Когда дело касается блогеров и соцсетей — реестр, блокировка, статья, протокол. Когда же речь идёт о реальных убийствах через банк и телефон, следы теряются по дороге между отделом «К» и ближайшим кофе-брейком. Почему мобильные операторы до сих пор живут в режиме «симки для всех»? Раз в месяц СТАБИЛЬНО появляются новости: «ФСБ изъяло тысячу поддельных сим-карт», но кто их выдал? Сотрудники на точках продаж, превращённые в статистов, повторяют, что «не могут проверять каждую личность». |
Возможно, потому что «бороться сложно», а «отчитаться легко». Сколько нужно смертей? Банки катают клиентов по кругу: «деньги ушли по согласию, вернуть невозможно». Операторы shrug: «номер оформил кто-то другой». Силовики закрывают дело фразой «неустановленные лица». И только матери, как у погибшей Марины, продолжают спрашивать — сколько ещё нужно смертей, чтобы мерзкая телефонная удавка перестала душить доверчивых людей?
13 ноября стало ещё одним днём статистики, который засчитают в графу «самоубийство». Но за каждым таким случаем — виртуальный след, реальные номера, конкретные банкоматы, конкретные сим-карты. Всё можно было вычислить, если бы хотелось. Преступление без ответственного Телефонные мошенники даже не прячутся — они живут в Telegram-каналах, торгуют базами клиентов банков, обсуждают, кого «развести». Это открытый рынок человеческих страхов. А настоящие структуры контроля тихо подмахивают очередное «поручение о профилактике». В кавычках — потому что профилактика начинается не с лозунгов, а с бизнеса операторов связи, банков и надзорных органов.
Когда-нибудь за это придётся ответить. Не мошенникам — они, как вирус, бессмертны в среде без иммунитета. Придётся отвечать тем, кто должен был поставить защиту, но поставил галочку. Марину нашли у базы с весёлым названием «Бодрость». Ирония момента будто нарочно прописана судьбой. Где-то там, за кулисами пиар-департаментов, сейчас уже наверняка готовят сухое заявление: «Ведётся проверка». Её результат предсказуем, как и любая официальная реакция: проверку проведут, выводы сделают, рекомендации направят. И всё. А через неделю другой «мошенник с Госуслуг» позвонит другой женщине и скажет: «Ваши деньги под угрозой». И история повторится — с неизменной бодростью государственного бездействия.
Потенциальные риски российского сегмента глобальной сети.
 |
Правительство РФ утвердило «Правила централизованного управления сетью связи общего пользования», которые описывают механизм реагирования на угрозы в Рунете. Постановление №1667 от 27.10.2025 опубликовано на официальном портале правовых актов.
Новые правила были разработаны в исполнение так называемого закона «о суверенном Рунете» (ФЗ-90), принятого ещё в 2019 году. Постановление Правительства РФ наделяет Роскомнадзор функциями оперативного реагирования на потенциальные риски для стабильности, безопасности и целостности российского сегмента глобальной сети. Нормативный акт вступит в силу 1 марта 2026 года и будет действовать вплоть до 1 марта 2032 года. Документ формализует совместную работу Минцифры, Роскомнадзора и ФСБ. Эти ведомства сформируют межведомственную комиссию, которая и будет принимать решение о введении централизованного управления «при возникновении угроз» работе сети. В рамках этого режима ведомства смогут применять следующие меры: - Обязательная фильтрация трафика через ТСПУ (технические средства противодействия угрозам). - Блокировка отдельных ресурсов или направлений трафика. - Изоляция российского сегмента сети от глобального интернета. |
К числу возможных угроз относятся перебои в доступе к телекоммуникационным услугам (включая вызов служб экстренной помощи), кибернетические атаки, несанкционированный доступ к управляющим системам, распространение запрещенного контента, а также нарушения в работе при взаимодействии между различными сетями.
В случае возникновения подобных угроз Роскомнадзор получает право корректировать маршруты трафика, резервировать линии связи, активировать средства защиты информации и устанавливать фильтры, а также издавать обязательные для исполнения распоряжения операторам связи и владельцам точек обмена трафиком.
Читать полностью »
Kroko ASR для FreeSWITCH
 |
Представляем Kroko ASR для FreeSWITCH: программа с открытым исходным кодом, преобразующая речь в текст в режиме реального времени. В течение многих лет прямая транскрибация звонков была привязана к облачным сервисам (speech2text.ru, curuscribe.ru, conspecto.ru, turboscribe.ai, audio-transcription.ru), что приводило к задержкам, проблемам с конфиденциальностью и непредсказуемым расходам. Мы считаем, что пришло время изменить это. С помощью Kroko ASR для FreeSWITCH теперь вы можете передавать аудиопоток ваших звонков напрямую на быстрый локальный движок распознавания речи, не требуя графического процессора. Вот что отличает его от других приложений: ► Оптимизирован для процессора: обрабатывает 8-10 параллельных потоков на ядро процессора. Не задействован графический процессор. Нет зависимостей. ► Точность на уровне Whisper / Parakeet: создана на основе моделей CC-BY и адаптирована для телефонии в режиме реального времени. ► Оперативная или облачная связь: Сохраняйте конфиденциальность данных, минимальную задержку и полный контроль. ► Простая интеграция: Используйте непосредственно в своем диалплане (kroko_transcribe) или через API (uuid_kroko_transcribe). ► Полностью открытый исходный код: расширяйте, адаптируйте и создавайте его самостоятельно, без привязки к поставщику. Эта интеграция обеспечивает мгновенную высококачественную транскрибацию в FreeSWITCH, что идеально подходит для поддержки клиентов, аналитики и голосовых роботов в режиме реального времени. Хотите получить ещё более высочайшее качество и поддержать наше предприятие? Подумайте о переходе на модели Kroko Pro: всего 25 долларов в месяц за корпоративную мини-АТС. (количество расшифровок неограниченно). Документация: https://docs.kroko.ai/demos/#kroko-module-for-freeswitch-real-time-transcripts GitHub: https://github.com/kroko-ai/integration-demos/tree/master/freeswitch-kroko Try Kroko ASR: https://www.kroko.ai P.S. Готовится релиз для Asterisk! |
Ликвидирована международная группа мошенников - операция SIMcartel
 |
Управление Национальной полиции по борьбе с киберпреступностью, специалисты 1-го отдела, 10-го октября 2025 года провели тщательно спланированную операцию"SIMcartel", в сотрудничестве с международной следственной группой Европола, Евроюста, полицией Австрии и Эстонии. В результате была ликвидирована группа, базируящаяся в Латвии, с обширной инфраструктурой сим-серверов, сим-шлюзов и сим-боксов (SIMbox), которая под видом легального бизнеса обеспечивала создание онлайн-анонимных учетных записей для осуществления связи и платежей, используемых для онлайн-мошенничества. Платформа SIMbox предлагала возможность использовать номера мобильных телефонов из более 80 разных стран, с помощью которых технически можно было анонимно регистрироваться в более чем 160 онлайн-сервисах. По оценкам расследования, за время работы инфраструктуры с помощью сервиса было создано около 50 миллионов онлайн-аккаунтов, с которых можно было осуществлять онлайн-мошенничество. В связи с существованием указанной платформы установлено, что пострадали жители Латвии, Эстонии и Австрии – соответственно, в каждой стране по этому факту ведется собственное расследование. В настоящее время полученная информация свидетельствует о том, что в Латвии от онлайн-мошенничества пострадали не менее 1500 человек с материальным ущербом около 420 000 евро, в то время как в Австрии масштабы мошенничества составили не менее 1700 человек, для которых материальный ущерб измеряется не менее чем в 4,5 миллиона долларов. 10-го октября сотрудники 1-го отдела по борьбе с киберпреступностью управления Национальной полиции, в сотрудничестве с антитеррористическим подразделением Национальной полиции "Омега", ликвидировали инфраструктуру преступного картеля и задержали четырех человек во время процессуальных действий, один из которых считается организатором незаконной службы, а остальные – техническими сотрудниками. Все задержанные лица - жители латвии, две женщины 1987 и 1970 г. рожд., и двое мужчин 1977 и 1982 г. рожд. В операции “SIMcartel” существенную помощь Государственной полиции оказали прокуратура Рижского судебного округа, Европол, Евроюст, австрийская полиция, эстонская полиция, CERT.LV и Фонд Shadowserver. |
Сим-банки против
 |
Интереснее история с ликвидированной в Нью-Йорке сетью GSM-устройств. Какие-то злоумышленники использовали эти устройства для «осуществления многочисленных угроз, связанных с телекоммуникациями, направленных против высокопоставленных чиновников правительства США, что представляло угрозу для операций по обеспечению безопасности, проводимых агентством», – говорится в заявлении Секретной службы. Сеть состоит из «более чем 300 совместно расположенных SIM-серверов и 100 тыс. SIM-карт на нескольких объектах» в радиусе 35 миль (56 км) от мест проведения встреч более чем 100 иностранных лидеров и их сопровождающих. «Помимо анонимных телефонных угроз, – говорится в заявлении, – эти устройства могут использоваться для проведения широкого спектра телекоммуникационных атак. Это включает в себя выведение из строя вышек сотовой связи, проведение атак типа «отказ в обслуживании» и обеспечение анонимной зашифрованной связи между потенциальными злоумышленниками и преступными группировками». Из этих слов явно следует, что ни с чем подобным, по крайней мере в таком виде, американская Секретная служба не сталкивалась. В России такие устройства принято называть «сим-бокс» или «сим-банк». Это устройство, позволяющее агрегировать в одном корпусе десятки сим-карт и удаленно управлять ими через интернет. Если какая-то отдельная сим-карта оказывается заблокирована, устройство тут же переключает свою работу на другую. Но главное – у этой техники нет территориальной привязки. Управлять работой сим-карт можно, находясь где угодно, в том числе в другой стране. Изначально эта технология применялась в банковской сфере и бизнесе для организации работы колл-центров, СМС-рассылки и внешней коммуникации офисов. Однако она оказалась очень удобна и для криминальной сферы: от организации относительно безобидного спама до деятельности телефонных мошенников. Именно эта аппаратура используется украинскими колл-центрами, занимающимися террором в отношении россиян. https://tass.ru/mezhdunarodnaya-panorama/25134869 |
Кибератаки спецслужб на мобильные устройства
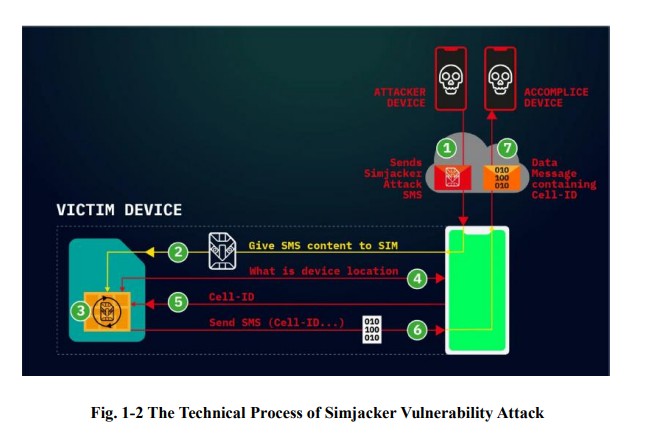 |
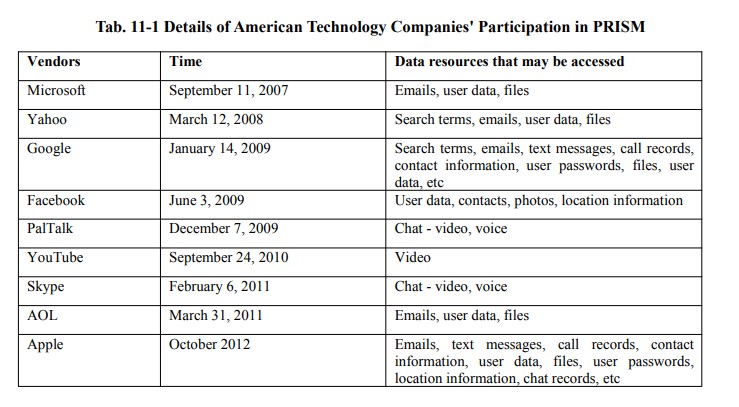
1. США, пользуясь доминирующим положением ИТ-компаний в области телекоммуникационных технологий и в глобальной цепочке поставок ИКТ-продуктов, проводят злонамеренные тайные кибероперации против иностранных государств. 2. Разведслужбы США с помощью заложенных американскими провайдерами и поставщиками оборудования «бэкдоров» осуществляют служку и сбор информации о деятельности государственных учреждений, компаний и частных лиц. 3. Широкий набор инструментов, включая уязвимости sim-карт, операционных систем, Wi-Fi, Bluetooth, GPS и мобильных сетей, являются лишь известной «вершиной айсберга» вредоносной деятельности американского разведывательного сообщества, нацеленной на кражу персональных данных, получение информации об устройствах, перехват телефонных звонков и определение геолокации. 4. Серьезную опасность представляет взятое на вооружение спецслужбами США коммерческое шпионское программное обеспечение. Посредством использования израильской программы Pegasus ФБР и ЦРУ осуществляли прослушивание телефонных разговоров глав государств, включая лидеров Франции, Пакистана, ЮАР, Египта и Ирака. 5. Обвинения Вашингтона в адрес других стран в нарушении безопасности цепочек поставок и проведении кибератак являются очередным примером американских двойных стандартов. Белый дом всеми силами стремится сохранить монополию в цифровой сфере, что подразумевает противодействие наращиванию потенциала развивающихся государств. https://colonelcassad.livejournal.com/9893188.html Радиоразведка (SIGINT) - это деятельность и область сбора разведывательных данных путем перехвата сигналов, будь то сообщения между людьми (коммуникационная разведка — сокращенно COMINT) или электронные сигналы, непосредственно не используемые в коммуникации (электронная разведка — сокращенно ELINT). Поскольку секретная информация обычно зашифровывается, радиотехническая разведка может обязательно включать криптоанализ (для расшифровки сообщений). Анализ трафика — изучение того, кто, кому и в каком количестве передает сигналы, — также используется для интеграции информации и может дополнять криптоанализ. Электронные средства перехвата появились еще в 1900 году, во время Англо-бурской войны 1899-1902 годов. В конце 1890-х годов Королевский военно-морской флот Великобритании установил на своих кораблях беспроводные устройства производства Marconi, а британская армия использовала некоторые ограниченные средства беспроводнойсвязи. Буры захватили несколько беспроводных устройств и использовали их для передачи важныхсообщений. Поскольку в то время англичане были единственными людьми, передающими радиосигналы, британцы не нуждались в специальной интерпретации сигналов, каковыми они и были. Зарождение радиоразведки в современном понимании относится к русско-японской войне 1904-1905 годов. В 1904 году, когда российский флот готовился к конфликту с Японией, британский корабль HMS Diana, стоявший в Суэцком канале, впервые в истории перехватил радиосигналы российского военно-морского флота, отправленные для мобилизации флота. Табличка ниже показывает, с какого года крупные компании "Big Tech" передают данные (и типы данных) американским спецслужбам. Любая продукция этих компаний заведомо скомпрометирована с точки зрения цифровой безопасности и приватности. |
   |
Caller ID Name будет обязателен
 |
Госдума приняла в первом чтении проект о борьбе с телефонным и интернет-мошенничеством, согласно которому все звонки на экранах мобильных телефонов должны быть промаркированы. |
Почему телефонные мошенники не исчезнут сами собой
 |
Цитирую (https://t.me/vmarahovsky/3308): — осведомлённость о том, что «есть телефонные мошенники и пытаются украсть деньги от имени банка»: 95%; — осведомлённость о том, что [иностранцы] представляются также ФСБ и полицией: 40%; — осведомлённость о том, что [иностранцы] представляются экс-коллегами по прежним работам: 25% |
Вчера я ссылался уже на ликбез Алексея Антонова про мошенников, которые инсценируют похищение родственника при помощи ИИ. Однако собранные Виктором данные показывают, что с точки зрения рациональных злодеев это пока что излишество.
Немного арифметики. Я не владею реальными данными по работе чёрных колл-центров, поэтому все цифры примерные (для наших расчётов достаточно и примерных цифр).
1. Оператор чёрного колл-центра получает 100 тысяч гривен в месяц (200 тысяч рублей).
2. Оператор делает 3 тысячи звонков в месяц.
3. В этих 3 тысячах звонков в 5% случаев на том конце провода оказывается потенциальная жертва, которая прожила последние 5 лет в дремучем лесу, и ещё не в курсе, что мошенники представляются банкирами.
4. Итого мошенники получают 150 наивных клиентов за 100 тысяч гривен, то есть платят по 650 гривен за одного тёплого Буратино.
Довольно дёшево, так как «средний чек» у мошенников значительно выше. При этом себестоимость лида (контакта потенциальной жертвы) можно резко снизить, если переключиться со схемы «звонит менеджер банка» на менее узнаваемую схему «звонит старший детектив ФСБ». Так как с этой схемой незнакомы уже 60% абонентов, стоимость дозвона сразу снижается до 55 гривен за одну жертву.
Эту сумму можно снизить ещё сильнее, если настроить массовый обзвон роботами, а человека подключать только после того, как жертва зацепится за первый крючок.
Как видите, выстраивать сложные декорации, добывая личную информацию и инсценируя потом фальшивое похищение, крупным чёрным колл-центрам пока что просто не нужно — это ниша для мелких креативных группировок. В итоге бухгалтерия крупняка выглядит примерно так:
1. Затраты на обработку одной жертвы, включая зарплату матёрых разводил и комиссии за вывод средств из России за рубеж: 2000 гривен.
2. «Средний чек», снимаемый с одной жертвы: 5000 гривен.
Всё. Рабочий контур выстроен, можно заливать в него десяти миллиардов гривен. Вопрос безопасности при этом даже не стоит, так как соседнее государство своих жуликов поощряет (не забывая собирать с них «налог»). Объём украденных в России денег составляет 250 млрд рублей в год и продолжает расти. Для понимания масштаба — это уже приблизительно четверть (!) от всего бюджета русской полиции (ссылка).
Если кто-то надеется, что волна телефонного мошенничества как-то схлынет сама собой, то я вынужден огорчить: очень непохоже на то, слишком уж рентабельность высока. Представьте себя на месте злодеев: вот у вас есть волшебный автомат, куда можно засунуть пачку денег и получить на выходе две с половиной пачки. Работает автомат на страданиях враждебных вам существ, которых вы не считаете за людей. Вы отойдёте от этого автомата добровольно?
Пожалуй, полуавтоматически проблема чёрных колл-центров может решиться только после выполнения целей СВО, так как релоцироваться в другую страну телефонные мошенники не смогут. Соседняя территория — единственный регион на нашей планете, где массовое мошенничество такого рода власти готовы терпеть. Даже Израиль и Канада, охотно дающие приют любым сквернавцам, чёрные колл-центры массово разворачивать никому не разрешат.
Однако как долго ещё будет идти СВО, мы не знаем. Напомню закон Линди: если вялотекущая война идёт три года, логично предположить, что и ещё три года она будет идти. Поэтому вполне вероятно, что в 2025 году уровень боли от мошенничества станет невыносимым, после чего наши власти начнут бороться с жуликами всерьёз.
Технически всё решается, тут сила на нашей стороне. Надо только понять, что сам по себе народ беззащитен — широкие массы населения не наберут достаточного иммунитета от жуликов никогда. Поговорка из девяностых — «лох не мамонт, лох не вымрет» — к сожалению, в данном случае верна. Поэтому тут потребуются неприятные политические решения. Например, такие:
1. Все звонки из-за рубежа предваряются пятисекундным голосовым сообщением от робота: «вам поступает звонок из-за рубежа, осторожно, это могут быть мошенники».
2. Контроль за оборотом сим-карт в России становится по-китайски жёстким: получить новую сим-карту сложнее, чем получить новый паспорт.
3. За массовые обзвоны следует немедленный вызов в полицию: даже если обзвоны делают мошенники разновидности «приглашаем в нашу стоматологию».
4. Нейросети прослушивают все звонки в режиме реального времени и моментально блокируют попытки «развода» — с последующим разбором полётов на предмет «через кого иностранцы получили русский номер телефона».
5. Полицейские агенты притворяются иностранцами, пытаясь купить сим-карты и кредитные карты для мошенничества. Тех, кто соглашается продать, отлавливают и профилактически сажают на 15 суток.
Полагаю, некоторые меры из этого очевидного перечня уже разрабатываются.
Конечно, все запреты можно обойти. Однако тут всё дело в деньгах. Сейчас, как я указал выше, мошенники могут закинуть в «волшебный автомат» 2000 гривен и вынуть оттуда 5000 гривен. Если все операции резко подорожают, получится другая арифметика: для получения тех же 5000 гривен придётся потратить на фальшивые сим-карты и тому подобное уже 25 000 гривен. Тогда чёрные колл-центры просто схлопнутся. С той стороны сидят моральные инвалиды, а не дураки: работать в минус они не станут.
Впрочем, разумеется, удалённое мошенничество никуда уже от нас не уйдёт: просто схемы станут другими. Более изощрёнными, с использованием хакеров и ИИ. Мы наблюдаем сейчас не рядовую инфекцию по типу финансовых пирамид, которыми Россия переболела в девяностых, а самую настоящую смену эпох. Как это ни странно звучит, воюющий с нами осколок СССР стал явочным порядком самой передовой страной мира: пока планета живёт ещё по инерции в более-менее индустриальном обществе, там уже наступил полноценный киберпанк. «Хай тек, лоу лайф», то есть «высокие технологии, низкая жизнь». С одной стороны, практическое остриё информационных технологий: огромная индустрия киберпреступлений, которые, кстати, даже близко не ограничиваются выманиванием денег по телефону. С другой стороны… ну, вы читаете новости, сами знаете, как там эти бедолаги живут.
GPT-4o3 уже умнее среднего фрилансера
 |
В тестах модель о3 показывает очень сильные результаты: и в математике, и в программировании, и в других областях. Мало того, модель набирает неожиданно высокие баллы в знаменитом испытании ARC-AGI, прохождение которого будет означать, что ИИ достиг уровня кандидата технических наук. Для сравнения: средний фрилансер выбивает на этом тесте 77%. Конечно, цифры весьма примерны, как это всегда бывает при тестировании умственных способностей, однако с практической точки зрения успешное прохождение теста ARC-AGI будет означать, что нейросеть справится с любым заданием не хуже, чем справился бы человек. Так вот, хронология прогресса: https://arcprize.org/blog/oai-o3-pub-breakthrough — в 2020 GPT-3 решал 0% задач теста; — в 2024 GPT-4о, текущая «рабочая лошадка» для тех, кто платит по $20 в месяц за подписку на ЖПТ, решала 5% задач; — осенью 2024 модель о1 решала от 8% до 32% задач, в зависимости от времени, которое ей давали на размышления; — сейчас, в декабре 2024, новая модель о3 решает от 76% до 88% задач теста. Ещё раз: средний фрилансер-удалёнщик, которого вы можете нанять на бирже Амазона за несколько долларов в час, решает 77% задач. Новая нейросеть о3 решает 76% задач в упрощённом своём варианте. Это уже игроки одной лиги. Пока что, правда, кожаные значительно дешевле. Фрилансеру за решение одной задачи надо заплатить пять долларов, а нейросеть о3 сожжёт на той же задачи вычислительных ресурсов на двадцать долларов. С продвинутым вариантом нейросети, которая по интеллекту где-то посередине между средним фрилансером и кандидатом технических наук, разница ещё больше: за одну задачу продвинутая о3 тратит 3,500 долларов (350 тысяч рублей). Но всё же это компьютерные технологии, тут свои скорости. Разрыв по цене в 4 раза — это ничто, в нейросетях дистанции такого размера преодолеваются через оптимизацию кода и новые приёмы очень быстро, зачастую за месяцы или даже недели. |
Напомню, что нейросеть, которая первой пройдёт тест, решив все 400 задач, получит миллион долларов в качестве поощрительного приза. Это вам не тест Тьюринга! Задачи кажутся глупыми, однако они проверяют сразу две критически важные способности: способность размышлять и способность давать точные ответы, то есть не путать цифры и не забывать, что замдиректора Жозефина Павловна занята с 15 до 16, так что в это время тревожить её нельзя. Надёжная память и мощный интеллект позволят роботу выполнять в реальной жизни уже не расстановку кубиков по клеткам, а более практичные задачи. Например, можно будет отдать нейросети такие команды:
- — дёрни всех наших клиентов с задолженностью больше 50 000 рублей, спроси, когда отдадут, сделай сверку, получи гарантийное письмо. (Робот сам разберётся, где взять список клиентов, как выйти на бухгалтера или директора с той стороны телефонного провода, как распечатать в 1С отчёт со сверкой и кому писать, если надо будет что-нибудь уточнить);
- — проверь документы, которые принёс нам Василий Кверулянтов, запроси у него недостающее, составь жалобу в суд;
- — разгреби 1800 писем в мои Входящих, удали спам, ответь на очевидные вопросы и перенаправь письма, с которыми должны разбираться другие люди, на более подходящие адрес. Из оставшихся писем выбери пять самых важных изложи мне их суть вслух, по 30 секунд на письмо;
- — сиди вот в этом окошке и принимай посетителей МФЦ. Вон в тех файлах подробное описание всех процедур, и вот тебе телефон админа, если столкнёшься с чем-нибудь новым. После каждого нового инцидента дополняй базу данных, чтобы ты и твои коллеги следующий раз могли разобраться с аналогичной проблемой самостоятельно;
- — обзванивай пенсионеров по этой базе, представляйся старшим инквизитором Интерпола и приказывай переводить деньги на безопасный счёт. Прослушай вот эту тысячу часов разговоров, чтобы понять суть наших приёмов;
- — читай крупные деловые американские СМИ, бери оттуда новости, которые укладываются в формат нашего сайта и излагай их в формате короткой статьи на русском языке, голосом.
https://olegmakarenko.ru/3160323.html
Возможность SSRF-атаки на Asterisk REST API
Каковы последствия SSRF-атак?Успешная SSRF-атака часто может привести к несанкционированным действиям или доступу к данным внутри организации. Это может произойти в уязвимом приложении или в других серверных системах, с которыми приложение может взаимодействовать. В некоторых ситуациях уязвимость SSRF может позволить злоумышленнику выполнить произвольную команду. Эксплойт SSRF, который приводит к подключению к внешним системам сторонних производителей, может привести к дальнейшим вредоносным атакам. Может оказаться, что они исходят от системы, в которой размещено уязвимое приложение. Распрeделённые SSRF-атакиSSRF-атаки часто используют доверительные отношения для усиления атаки из уязвимого приложения и выполнения несанкционированных действий. Эти доверительные отношения могут существовать в отношении сервера или в отношении других серверных систем в той же организации. SSRF-атаки на Астериск-серверПри SSRF-атаке на сервер злоумышленник заставляет приложение отправить HTTP-запрос обратно на сервер, на котором размещено приложение, через его сетевой интерфейс обратной связи. Обычно это включает в себя указание URL-адреса с именем хоста, таким как 127.0.0.1 или localhost. |

Content-Length: 118
Api=http://localhost:8080/ari/applications